
The taming of the scoundrel
February 1, 2016
Do you like to develop databases? No, not the modern NoSQL, but good old-fashioned relational ones, where you can describe the relations and the stored procedures for the data access and logic. May be you develop databases for PostgreSQL? If so, that`s excellent — this post is definitely for you.
I guess there is no use describing the advantages of PostgreSQL. I will just say in short that this is a modern fast DBMS with rich capabilities and it is definitely able to compete with the commercial database management systems. The fact that PostgreSQL is released under the free license similar to BSD license (that allows to use it in the commercial projects without license fee and makes the source code fully accessible without the necessity to open your code when making changes) and that it is actively developing at the moment (9.5 version with some pleasant improvements) has been recently released, in January 2016) allows us to say that PostgreSQL could be one of the best DBMS for now. So what prevents PostgreSQL from gaining popularity among the developers?

One of the factors is the quite limited number of tools both for databases development and for further maintanence. There are, of course, JDBC drivers for PostgreSQL and all the JDBC using tools work with it, but these tools are usually of general purpose and they are not always able to use the particular DBMS special features.
What development special features are we talking about? For example, when modifying the existing DB objects (usually tables or views), you can quite often face the object change error as it is forbidden by PostgreSQL because of the dependent objects presence.
ags=# create table t1 (f1 text);
CREATE TABLE
ags=# create view v1 as select * from t1;
CREATE VIEW
ags=# alter table t1 alter column f1 type char(5);
ERROR: cannot alter type of a column used by a view or rule
DETAIL: rule _RETURN on view v1 depends on column "f1"Many developers have already got tired of this special feature, it is recorded in TODO wiki.postgresql.org/wiki/Todo#Views_and_Rules and has some possible handling variants (for example: mwenus.blogspot.nl/2014/04/postgresql-how-to-handle-table-and-view.html).
Here’s another example. Did you have situations like that: you’ve created a stored procedure, began actively using it and, as it usually happens, you wanted to modify it after a while. Only when you began figuring out why logic was working only partially, you noticed that in fact you’d created an additional procedure with a new signature (which was being used by a code’s part) and the other code’s part used a negligently left old procedure?
ags=# \df f1
List of functions
Schema |Name |Result data type | Argument data types | Type
--------+-----+-----------------------+------------------------+---------
public | f1 | void | | normal
public | f1 | void | p1 integer | normal
(2 rows)It is very easy to face such situation, and I think, lack of grouping objects like Oracle, that logically unite the stored procedures and are installed to the base usually in one package, which excludes the appearance of «forgotten» objects, enables such situations. It goes without saying, that if you’re testing your code, probability of such objects change to real ones is low, however such actions encrease the maintenance complexity.
What should you do to compare two DBs and generate a script of transformation from one base to another? You might likely want to use Liquibase, however, you’ll get disappointed when you’ll learn that Liquibase doesn’t know anything about the solution methods of dependencies problems mentioned above.
We faced the similar questions about three years ago when we began the migration process from MSSQL to PostgreSQL. At the time we were using Redgate SQL Source Control to work with MSSQL, so we were really dissatisfied with the lack of a similar tool for PostgreSQL management. We were so annoyed that we decided to create our own tool capable to monitore the changings in the DB and to create the selected objects migration scripts both in interactive and automatic mode.
The decision of development platform selection has come quite quickly as we programme mostly by means of Java. The application began to develop as a set of Eclipse additions after some cut and try iterations.
That’s exactly how our product pgCodeKeeper has after a while come to life.
In a nutshell, its work can be described as follows: DB objects are saved to the disk in the form of the Eclipse project, which can be put into the version storage system later on if you wish. By comparing DB with the project or some project branch later on, it is possible to generate both migration scripts from DB (for the object states transfer from the project to DB) and into it. Due to the fact that we use ANTLR grammar to analyze the objects, we can build object dependency columns worked out quite well. It leads to the correct migration scripts creation (considering the existing dependencies problems mentioned above).
pgCodeKeeper usage can help to organize workflow of making changes in DB. We successfully use the following scheme:
The first two steps are done by a developer, the third is done by an inspector, the fourth and the fifth can be done by the person maintaining DB. The fourth and the fifth steps can also be done in automatic mode and this can be very comfortable for continuous Deliver. But we won’t talk about it in this article.
Not all actions are done with the help of pgCodeKeeper in the described working process. For example, creation of a new branch in the version control system is made by EGit addition for Eclipse, whereas the merge request code review is made with the help of GitLab.
So, the main aim of pgCodeKeeper is comparing preliminarily created project with database instance, specifying modified objects and applying the changes either to the project from DB (project files modification) or to DB from the project (via migration script creation).
After a while, our project was successfully developing, and at a certain point there were no doubts that pgCodeKeeper handles current requirements for our internal DB maintenance perfectly, however product backlog is by no means empty. It is filled with the features and errors which can potentially be met in other develovers’ DB. It became clear that pgCodeKeeper would either remain as a part of a corporational project (and probably would move to the stagnation stage as practically all the requested features have been done), or would try to enter the public market and get the answers to the following questions with the help of the feedback:
Now we’re ready to release pgCodeKeeper into the public beta testing with the only usage condition — feedback provision. Would anybody like to try the product?
So, I hope that if you’ve read up to this moment, you’ve got interested enough to try pgCodeKeeper. Ready? Let’s start.
As I have written before, pgCodeKeeper has started to represent a set of the Eclipse platform additions at the end of its evolutionary process. It means that it is multiplatform and it works both under Linux and Windows. It will certainly work under other platforms where the Eclipse platform can be started, but we use only these two.
For the pgCodeKeeper correct work the Eclipse Juno platform or greater is required, however this notice is for those who want to install into the existing Eclipse instance. For new Eclipse installations use the latest version from eclipse.org/downloads. You can install Eclipse IDE for Java Developers (as among other issues the additions for Git integration are already installed in it and it is relatively small) or choose any tool you like (don’t forget: Eclipse is a Java application, and you should install JRE/JDK before to make it work).

Choose the meny options Help — Install new software and enter update site URL: pgcodekeeper.ru/update/release
Choose and install pgCodeKeeper addition. Reload the Eclipse and if we see pgCodeKeeper project in the new projects wizards list, then the installation mission is complete.
PgCodeKeeper work is to compare objects in the project and DB. Before creating a project you should already have a DB, from which you want to make initial copy of the project. Let’s create a base and try to go through the DB development process.
$ psql -X <<SQL
create database dev;
\c dev
create table t1 (f1 text);
create view v1 as select * from t1;
create view v2 as select * from v1;
create function f1(p1 int) returns v2 as 'select * from v2 limit 1' language sql;
SQL
CREATE DATABASE
CREATE TABLE
CREATE VIEW
CREATE VIEW
CREATE FUNCTION
$ psql dev
psql (9.3.10)
Type "help" for help.
(ags@10.84.0.6:5432) 15:11:08 [dev] =# \d \df
List of relations
┌────────┬─────┬───────────────┬──────────┐
│ Schema │Name │ Type │ Owner │
├────────┼─────┼───────────────┼──────────┤
│ public │ t1 │ table │ ags │
│ public │ v1 │ view │ ags │
│ public │ v2 │ view │ ags │
└────────┴─────┴───────────────┴──────────┘
(3 rows)
List of functions
┌────────┬─────┬───────────────────────┬────────────────────────┬─────────┐
│ Schema │Name │ Result data type │ Argument data types │ Type │
├────────┼─────┼───────────────────────┼────────────────────────┼─────────┤
│ public │ f1 │ v2 │ p1 integer │ normal │
└────────┴─────┴───────────────────────┴────────────────────────┴─────────┘
(1 row)So, we have a database, it’s time to have fun and to write some code. Let’s change the table t1:
(ags@10.84.0.6:5432) 15:12:28 [dev] =# alter table t1 alter column f1 type char(5);
ERROR: cannot alter type of a column used by a view or rule
DETAIL: rule _RETURN on view v1 depends on column "f1"
TIME: 2,393 мсIt is to be expected that we cannot perform the requested action, because v1 expression depends on t1 table. Moreover, to delete v1 we’ll have to delete both v2 and f1
(ags@10.84.0.6:5432) 15:16:05 [dev] * =# drop view v1;
ERROR: cannot drop view v1 because other objects depend on it
DETAIL: view v2 depends on view v1
function f1(integer) depends on type v2
HINT: Use DROP ... CASCADE to drop the dependent objects too.
TIME: 1,631 мсWell... it looks like we are in a slight trap, now we’ll have to go to some great scripts (for example, similar to that I’ve written about above… however, they don’t work with all objects that can get into the dependencies columns) or use pgCodeKeeper (there is one more variant to make a cascading delete of the expression and dependent objects and to restore the lost objects from the preliminarily saved dump, but we won’t use this option).
It’s high time to create a DB maintenance project.
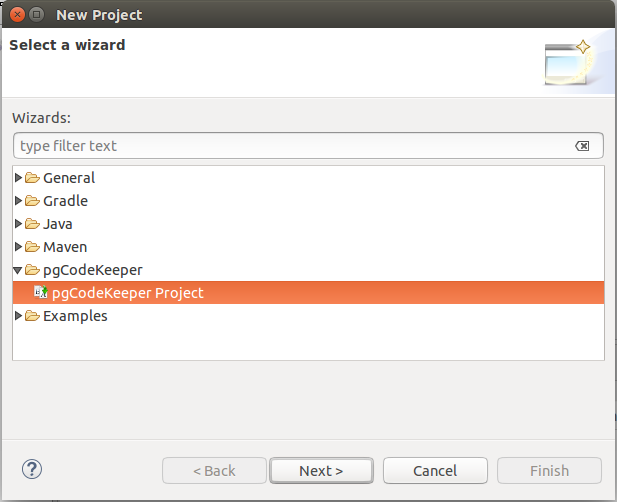
Enter a new project’s name:
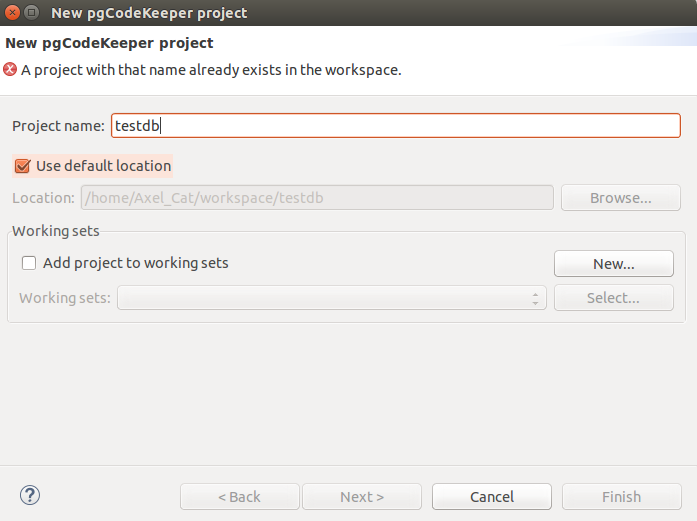
Configure a source for DB (yes, you can face the slightly unevident moment of a new source adding, but be patient, we’ll surely upgrade it in the future). Personally, I keep my passwords in .pgpass and pgCodeKeeper is able to take them from it, but if you don’t use them, fill in the password field in wizard.
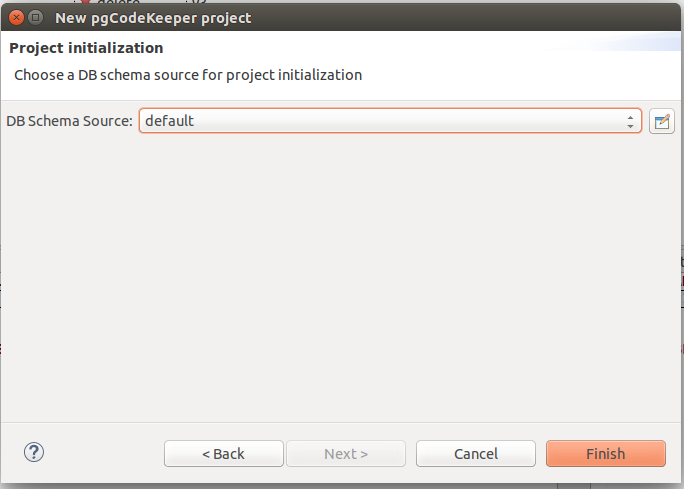
The project creation is complete, press «Finish». If you did everything right, a new project will be initialized and filled with the DB objects.
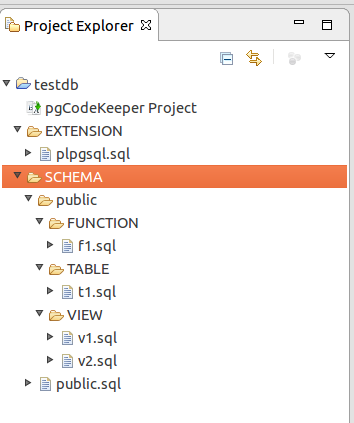
DB object in project — is a readable file, which among other things can be edited.
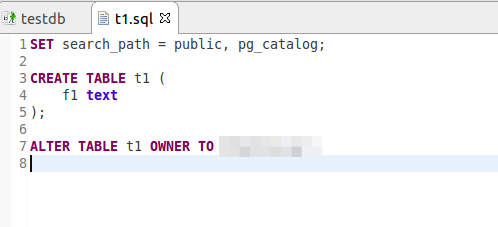
At the moment pgCodeKeeper is not positioned as a fully-featured SQL or PL/pgSQL code editor, but sometimes — as, for example, in this case, - there is nothing better than to edit a file directly in the editor. Let’s change the only field’s type from text to char(5).
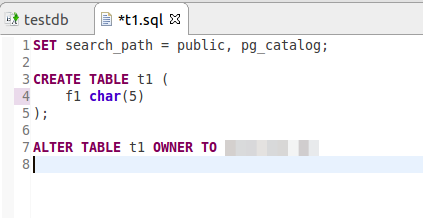
Move to the main project panel (lower Tab - «Update DB») and press «Get changes». pgCodeKeeper has displayed the list of objects, which differ both in DB and in the project. Diff panel shows the detailed changes in DB objects.
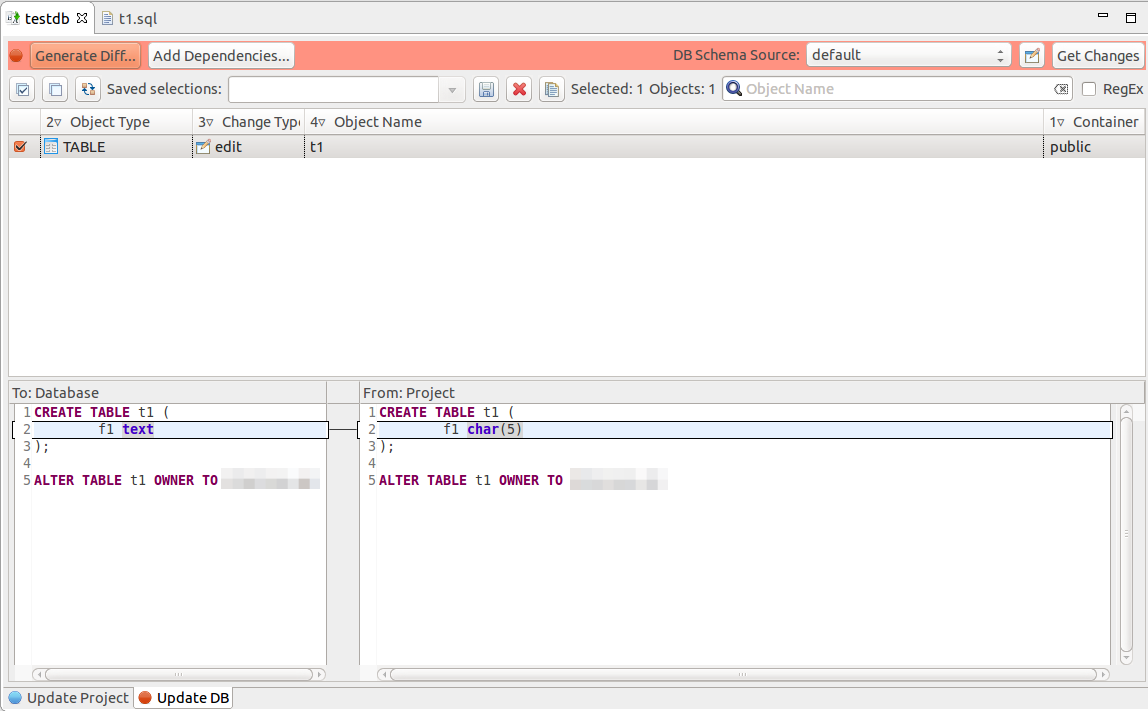
Now there is one little thing left, tick the DB objects which we want to synchronize with the project objects and press «Generate script». pgCodeKeeper will helpfully report that generated script contains dangerous instructions, which can lead to data loss, and will generate the following script:
SET TIMEZONE TO 'UTC';
SET check_function_bodies = false;
-- DEPCY: This FUNCTION depends on the COLUMN: t1.f1
DROP FUNCTION f1(p1 integer);
-- DEPCY: This VIEW depends on the COLUMN: t1.f1
DROP VIEW v2;
-- DEPCY: This VIEW depends on the COLUMN: t1.f1
DROP VIEW v1;
ALTER TABLE t1
ALTER COLUMN f1 TYPE char(5); /* TYPE change - table: t1 original: text new: char(5) */
-- DEPCY: This VIEW is a dependency of FUNCTION: f1(integer)
CREATE VIEW v1 AS
SELECT t1.f1
FROM t1;
ALTER VIEW v1 OWNER TO ags;
-- DEPCY: This VIEW is a dependency of FUNCTION: f1(integer)
CREATE VIEW v2 AS
SELECT v1.f1
FROM v1;
ALTER VIEW v2 OWNER TO ags;
CREATE OR REPLACE FUNCTION f1(p1 integer) RETURNS v2
LANGUAGE sql
AS $$select * from v2 limit 1$$;
ALTER FUNCTION f1(p1 integer) OWNER TO ags;Hooray!!! Couple of mouse clicks (if not considering project initialization) and we can generate migration scripts! The received script can be installed both independently by means of pgAdmin/psql and also by means of pgCodeKeeper. As far as DDL instructions in PostgreSQL are transactional, I mention the necessity of script execution in one transaction (key — 1 in psql) when installing similar scripts to prevent the DB inconsistent state in case of a script execution error.
If to compare the project and DB again, we’ll see that the objects in the project and DB… Differ?!
Don’t panic, it is connected with the fact that when we were making changes in the project manually, we wrote a character type short form as char, and it is now displayed in a full form in DB.
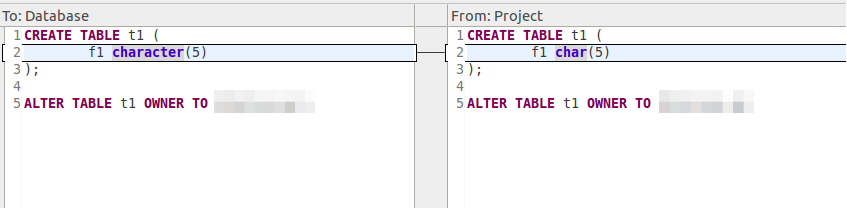
To update a project switch to lower tab «Update project», press «Get changes», select the required objects and press «Apply selected changes». After performing these actions DB objects and project objects will become identical.
As far as the product was initially developed for internal DB, only the object types used by us were tested in the first place, some are not supported yet (for example, FOREIGN TABLE). PgCodeKeeper doesn’t support operation with all PostgreSQL versions, at the moment operation with 9.3 version and greater is guaranteed (perhaps, it will operate with 9.1-9.2 versions, but not older — we need to check).
Today you’ve got acquainted with a new product making PostgreSQL operation easier. I’ve told about main capabilities of the product, not touching upon the following: manual dependencies adding (if our parser hasn’t managed you can always direct it), operation with version control systems, pgCodeKeeper operation in automatic, non-interactive mode.
The article contains neologisms, jargonisms and several obsolete expressions. I’ve always specified the word or expression meanings which define them in English best of all.
At the moment pgCodeKeeper is being registrated in the register of Russian software according to the RF Government Decree No. 1236 of November 16, 2015 «On prohibition on the admission of software, originated from foreign states, for the purposes of buying execution to ensure the government and public needs» www.garant.ru/hotlaw/federal/671898 and it means that pgCodeKeeper will be able to take part in the import substitution programme in the nearest future.
pgCodeKeeper greatly eases PostgreSQL databases maintenance (even habituation effect was observed).
How interesting have you found pgCodeKeeper?